The data included in the database EMMA(videos, Kinect features, annotations) are publicly available to the research community.If you are using EMMA in your research, please cite the following paper (the paper describing the annotation via crowd-sourcing is under revision)
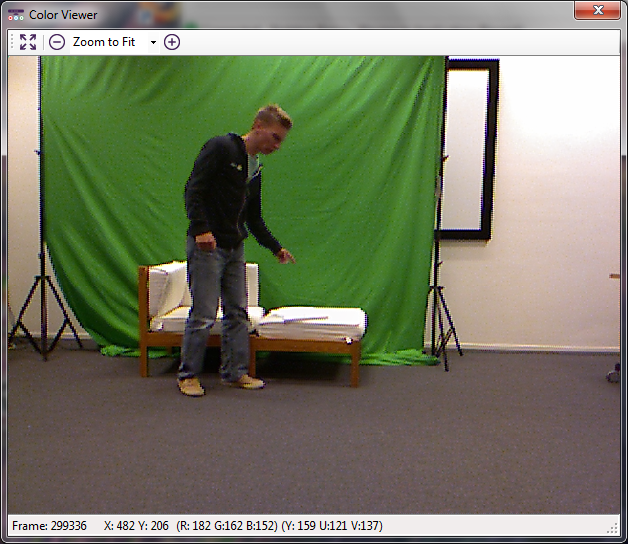
EMMA is a collection of videos, recorded in the lab of the Interactive Intelligence Group of Delft University of Technology. We employed young Dutch actors to portray certain daily moods, occurring without interaction, such as sadness, anxiety and amusement.
To make sure the actors were "into the mood", we induced to them the desired moods with music, inspired them with scenarios (receiving a phone call, looking for something they lost, etc.),
and let them free to improvise according to their felt mood and the situation.
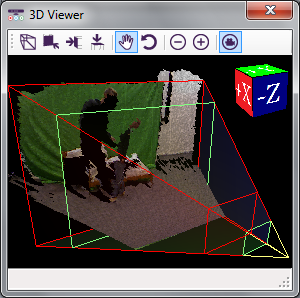
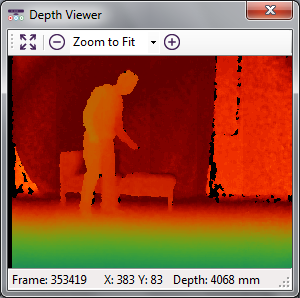
We recorded with two cameras, one focused on the face and one capturing face and body, and with Microsoft Kinect, located at a distance of approximately 2 metres away from the actors.
All sensors remained at fixed positions, to resemble a typical smart ambience equipped with sensors. The actors could move around the setting, including sitting on the chair/couch, walking and standing. Due to the actors' movements, the actor's face is not properly captured in a lot of frames.
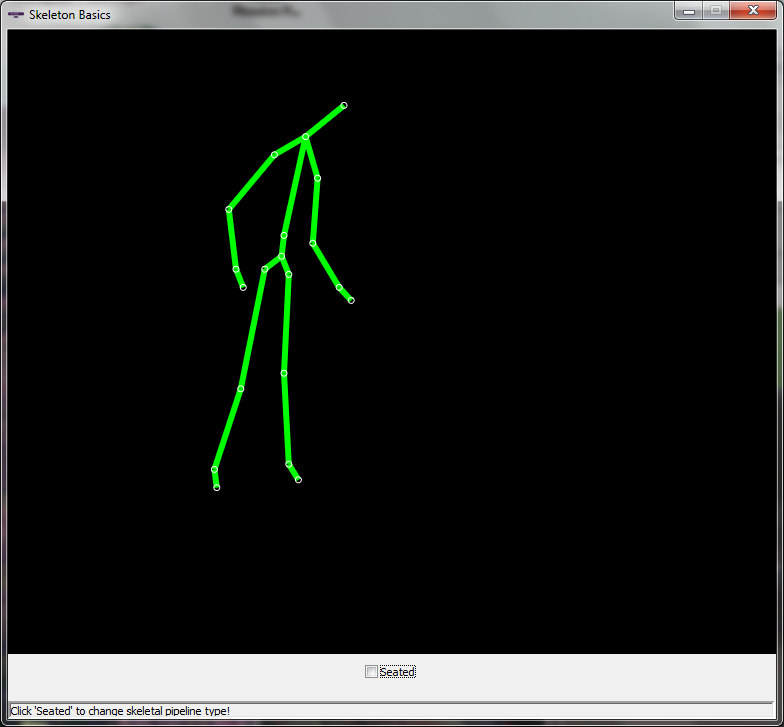
We used the Kinect, to extract postural features, such as the joints and the rotational speed of the joints. We extracted the joints for each video offline in two modes: seated (10 joints) and standing (20 joints), each mode optimized for a different situation. Due to the suboptimal distance of Kinect from the actors, the skeleton joints are not detected in all frames of the videos. The joints are transcribed in separate text files, which can be downloaded under the title "Kinect joints".
The videos take up 410 GB, with a total reproduction time of 7.5 hours.
Examples of the videos can be viewed here (x2 speed):
Annotations
We wanted to annotate the videos in terms of the continuous perceived emotion and the mood felt over the whole episode. Since we had a vast number of videos, we crowd-sourced the annotations, reaching out to a massive number of people with various demographics. Both emotions and mood were annotated in terms of the affective dimensions of valence and arousal. The continuous annotation of emotions was done with the G-Trace1 while watching the video. The mood was annotated in the end of the video, in terms of SAM (Self-Assessment Manikins)2, the Affect Button3, and a categorical description (positive/neutral/negative for valence, low, medium, high for arousal).
For a better understanding, you can visit here /. For more details for the process and the evaluation, see the upcoming paper on EMMA.
1 Cowie, R. & Sawey, M., 2011, GTrace-General trace program from Queen’s, Belfast. 2 Bradley, M. M. & Peter, J. L., 1994, Measuring emotion: the self-assessment manikin and the semantic differential, Journal of behavior therapy and experimental psychiatry , Volume 25(1) , pp. 49-59. 3 Broekens, J. & Brinkman, W. P., 2009, Affectbutton: Towards a standard for dynamic affective user feedback, International Conference on Affective Computing & Intelligent Interaction .
Crowdsourcing and Filtering
We used the Microworkers Platform: http://www/Microworkers.com/. At this moment, we have finished the annotation of the data-set EMMA-faces. We are sending an open call to researchers to annotate the dataset EMMA-body and enrich this work!
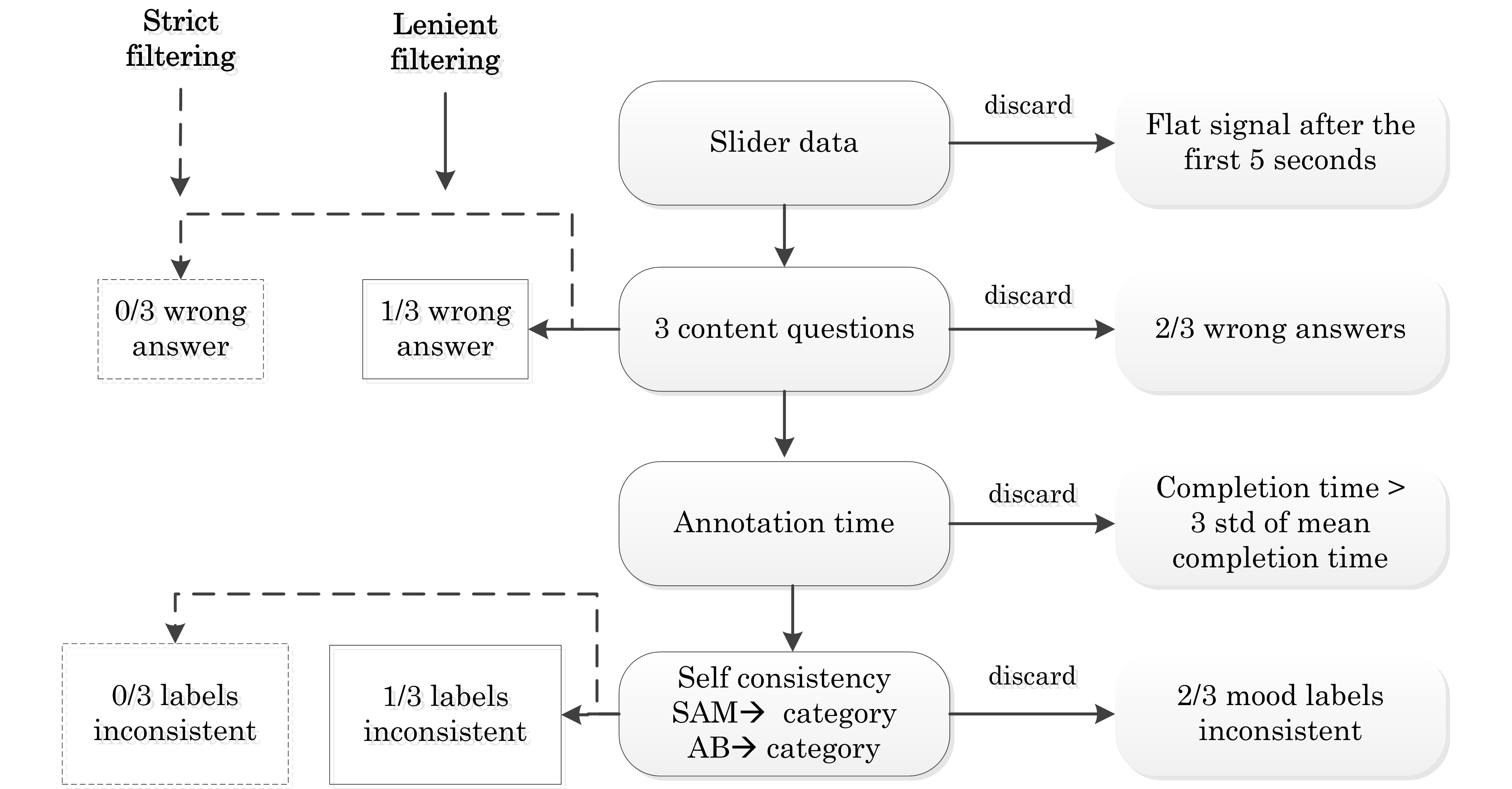
Anonymity in crowd-sourcing encourages cheating, so we had to filter out the noisy annotations. We applied multiple layer filtering, as seen in the cascade below:
We based our analysis on the most lenient filtering, but the researchers are free to apply their own (or no) filtering. Therefore, we provide both the raw annotations and the ones after the most lenient filtering.
More details on the experimental set-up and results can be found in the upcoming paper. Keep visiting the website, to keep track of the updates!
We provide three files for valence and three for arousal containing all the emotion annotations (due to the size limits of each excel sheet). The researcher can run a script to extract the continuous emotion annotations under the desired "rid". You can find which rid corresponds to which clip from the mood annotation files.
Facial expression
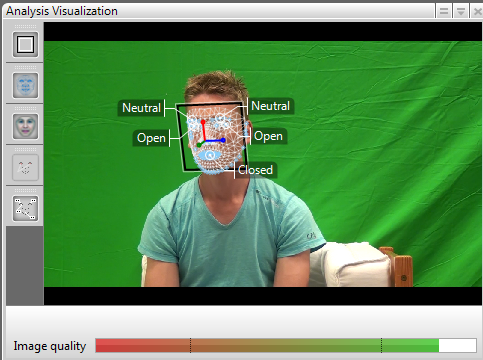
We extracted facial expression features (position of facial features and head orientation) using the software FaceReader